
1 Introduction
Binary machine failure prediction using machine learning is a technique employed to anticipate the occurrence of failures or malfunctions in a binary system or machine. With the increasing complexity of modern machines, the ability to predict and prevent failures becomes crucial for optimizing performance, reducing downtime, and avoiding costly repairs.
Machine learning algorithms play a vital role in this prediction process by analyzing historical data and identifying patterns or anomalies that indicate potential failures. These algorithms learn from past failure instances, considering various factors such as sensor readings, environmental conditions, maintenance records, and other relevant parameters.
The predictive models are trained on labeled datasets, where each instance is associated with a failure or non-failure outcome. Common machine learning techniques used for binary machine failure prediction include logistic regression, decision trees, random forests, support vector machines (SVM), and neural networks.
During the training phase, the algorithms learn the relationships between input features and failure occurrences, thereby enabling them to make accurate predictions on unseen data. Feature engineering, which involves selecting or transforming relevant input variables, is an essential step in improving the model’s performance.
Once the model is trained, it can be deployed to make real-time predictions on new data streams. By continuously monitoring machine inputs and comparing them to the learned patterns, the system can generate alerts or take preventive actions whenever a potential failure is detected. This proactive approach helps minimize unexpected downtime, reduce maintenance costs, and improve overall operational efficiency.
Binary machine failure prediction using machine learning is widely applied across various industries, including manufacturing, power generation, healthcare, transportation, and more. By leveraging the power of data and advanced analytics, it offers a valuable tool for optimizing maintenance strategies, enhancing productivity, and ensuring the reliability of critical systems.
2 Importing the relevant libraries and dataset 🛠️
First, we import the required libraries which we will use to perform the current analysis.
Great ! We have all the libraries loaded. Next, we are gonna load the required dataset for conducting the machine failure classification analysis.
We will use one dataset for the purpose of exploratory data analysis and training the classification model while the test dataset for testing the classification model on a completely new dataset.
After reading the data, let us see how the train dataset looks like.
| id | Product ID | Type | Air temperature [K] | Process temperature [K] | Rotational speed [rpm] | Torque [Nm] | Tool wear [min] | Machine failure | TWF | HDF | PWF | OSF | RNF |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | L50096 | L | 300.6 | 309.6 | 1596 | 36.1 | 140 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | M20343 | M | 302.6 | 312.1 | 1759 | 29.1 | 200 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | L49454 | L | 299.3 | 308.5 | 1805 | 26.5 | 25 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | L53355 | L | 301.0 | 310.9 | 1524 | 44.3 | 197 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | M24050 | M | 298.0 | 309.0 | 1641 | 35.4 | 34 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | M24300 | M | 298.4 | 308.9 | 1429 | 42.1 | 65 | 0 | 0 | 0 | 0 | 0 | 0 |
From Table 1, we can observe that there are multiple process parameters present in the dataset which can help us analyse whether a machine undergoes failure. We can also observe that there are multiple abbreviations in this dataset. Let us try to understand what do these abbreviations mean :
- Tool Wear Failure (TWF): A type of machine failure which is associated with excessive tool wear.
- Heat Dissipation Failure (HDF): Machine failures which are associated with high process temperatures.
- Power Failure (PWF): Machine failures which are associated with power readings above or below a certain value.
- Overstrain Failure (OSF): Machine failures which are associated with high strain values.
- Random Failure (RNF): Machine failures which maybe associated with random conditions.
3 Data cleaning
3.1 Check for null values
As a part of checking for the cleanliness of the dataset, let us visaulise the presence of null values for each of the variables.
As we can observe from figure Figure 2, there are no missing values for any of the variables in the dataset. As a result, the dataset can be considered clean for further analysis.
3.2 Removal of variables
After studying for the presence of null values, we now remove the variables that do not provide any extra insights into our analysis.
df_train <- df_train %>% select(-c(id,`Product ID`))3.3 Cleaning the variable names
The current dataset contains variable names which are not ideal for data wrangling and EDA. Hence, we will try to remove any unnecessary white space and special characters for each of the variable names.
df_train <- clean_names(df_train)
head(df_train)# A tibble: 6 × 12
type air_temperature_k process_temperature_k rotational_speed_rpm torque_nm
<chr> <dbl> <dbl> <dbl> <dbl>
1 L 301. 310. 1596 36.1
2 M 303. 312. 1759 29.1
3 L 299. 308. 1805 26.5
4 L 301 311. 1524 44.3
5 M 298 309 1641 35.4
6 M 298. 309. 1429 42.1
# ℹ 7 more variables: tool_wear_min <dbl>, machine_failure <dbl>, twf <dbl>,
# hdf <dbl>, pwf <dbl>, osf <dbl>, rnf <dbl>4 Exploratory Data Analysis
After obtaining the cleansed dataset, we now try to visualise the relationship of each of the variables and attempt to obtain critical insights.
4.1 Type of machine
There are a total of 3 types machines in this dataset. These are encoded as:
- L (Light)
- M (Medium)
- H (Heavy)
Let us see the number of machine failures for each of the machine types.
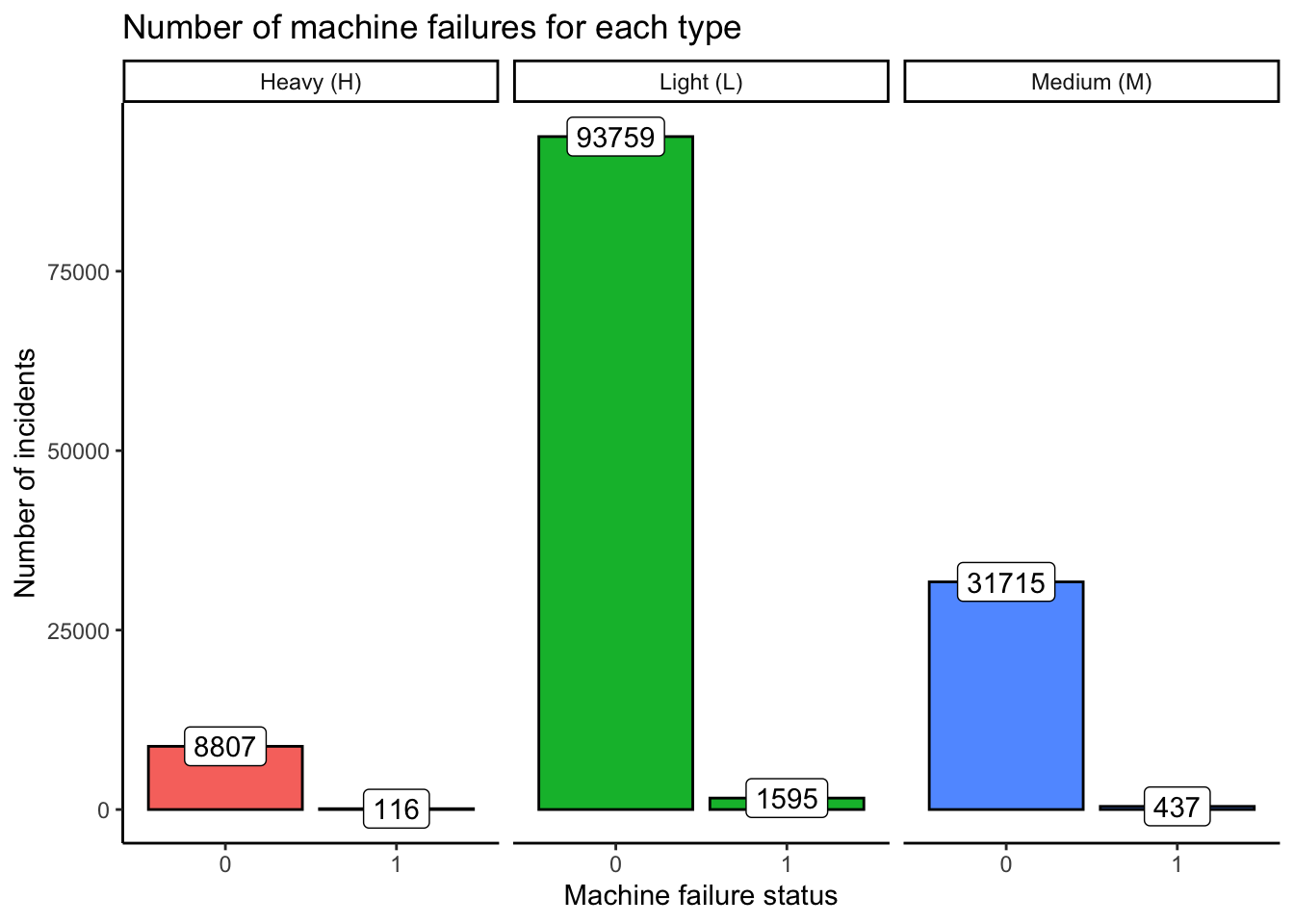
Figure Figure 3 illustrates the number of failures observed for each machine type. The failures constitute:
- 1 % of the incidents for machine type “H”
- 2 % of the incidents for machine type “L”
- 1 % of the incidents for machine type “M”
📵 Hence, we can observe that the number of failure cases are fairly evenly distributed among each of the machine types. 📵 .
4.2 Air and process temperatures
Temperatures can play a critical role in relation to machine health. In this dataset, we have air and process temperatures. The difference of these values could allow us to understand the overall heat dissipation of the machines. Analysing these variables may allow us when do the machines undergo overall failure as well as heat dissipation failure (HDF).
Let us first study the distribution of the temperature values.
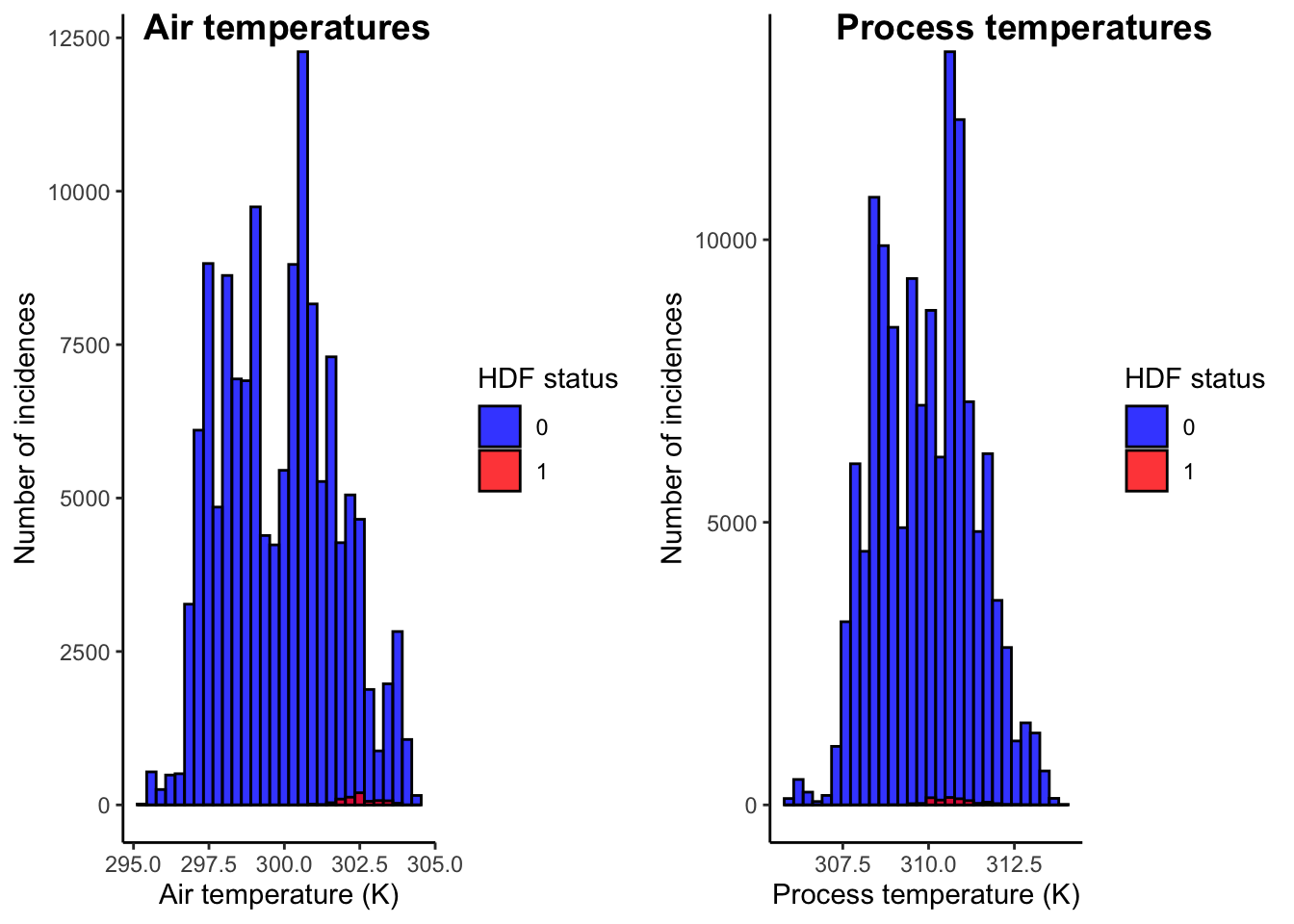
As we can observe from Figure 4, majority of the heat dissipation failures have occurred at relatively higher values of air temperatures. These air temperatures are observed to be around 302.5 K. Higher air temperatures invariably leads to lower value of heat dissipation which may cause heat dissipation failure and subsequently, machine failure.
Heat dissipation values are governed by the following heat transfer equation.
\[ \boxed{\Delta H = mC_p(T_{process} - T_{air})}\] Based on the above equation, let us now study how the difference between process and air temperatures vary for heat dissipation failures.
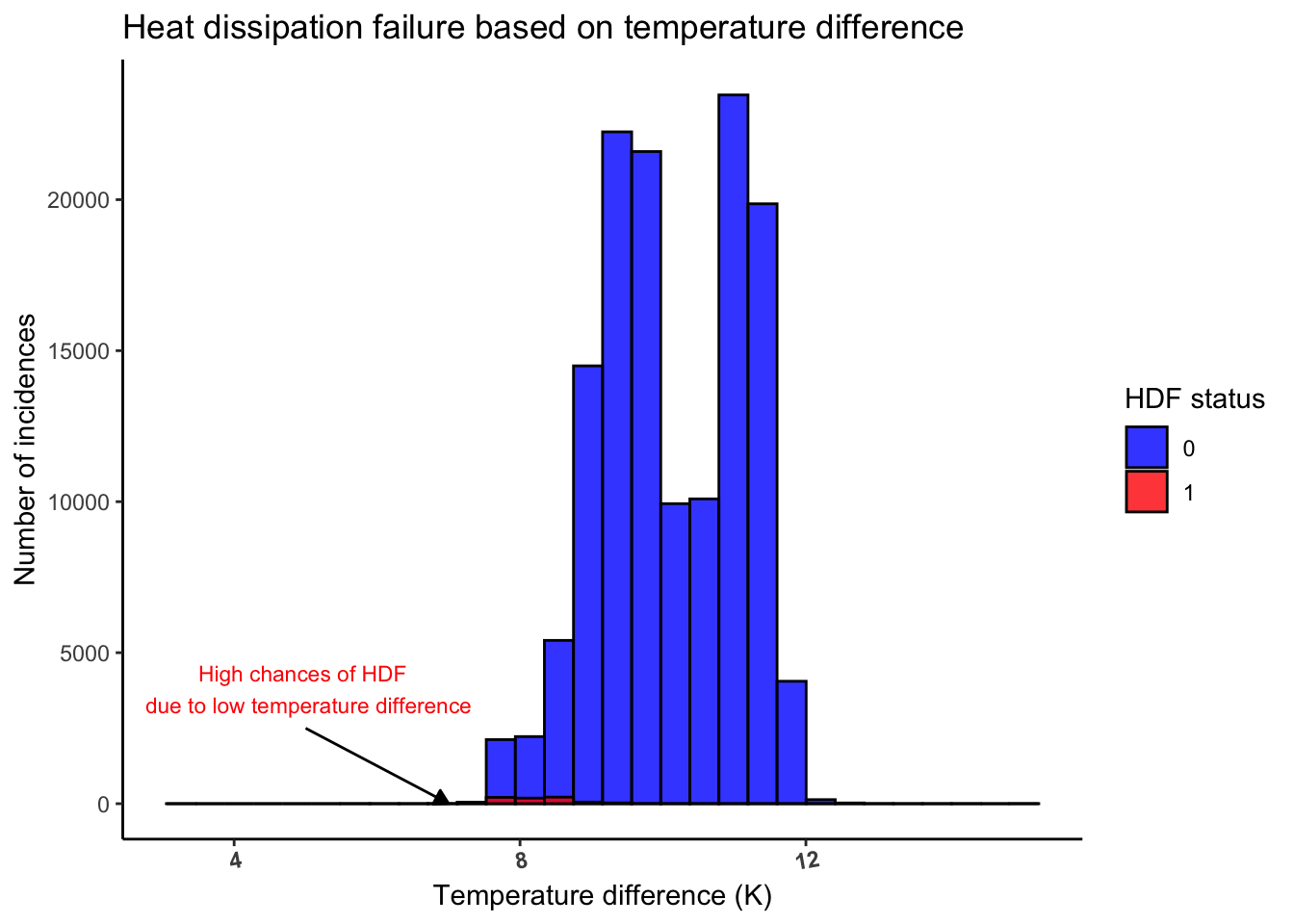
As illustrated by figure Figure 5 and based on the heat transfer equation, we can observe that
⚠️ the majority of the heat dissipation failures occur at low temperature differences between process and air temperatures. ⚠️ .
4.3 Torque and Tool rotation speed
The torque of a machine can be defined as the amount of rotational energy required to perform mechanical work. As a result of torque applied, a machine element, such as the tool in this case rotates at a particular speed. This speed of rotation is measured by the tool rotation speed in revolutions per minute (RPM).
In addition to the above definitions, the product of the torque and the tool rotation speeds give us the value of the power consumption of a machine. The equaiton for the same is as follows :
\[ \boxed{P = \omega T} \] Where,
\(P =\) Power consumption of the machine in Watts
\(T =\) Torque in Nm
\(\omega = 2\pi N/60\), with \(N\) being the tool rotational speed (RPM)
Let us now visualise the torque and tool rotation speed values for each machine type.
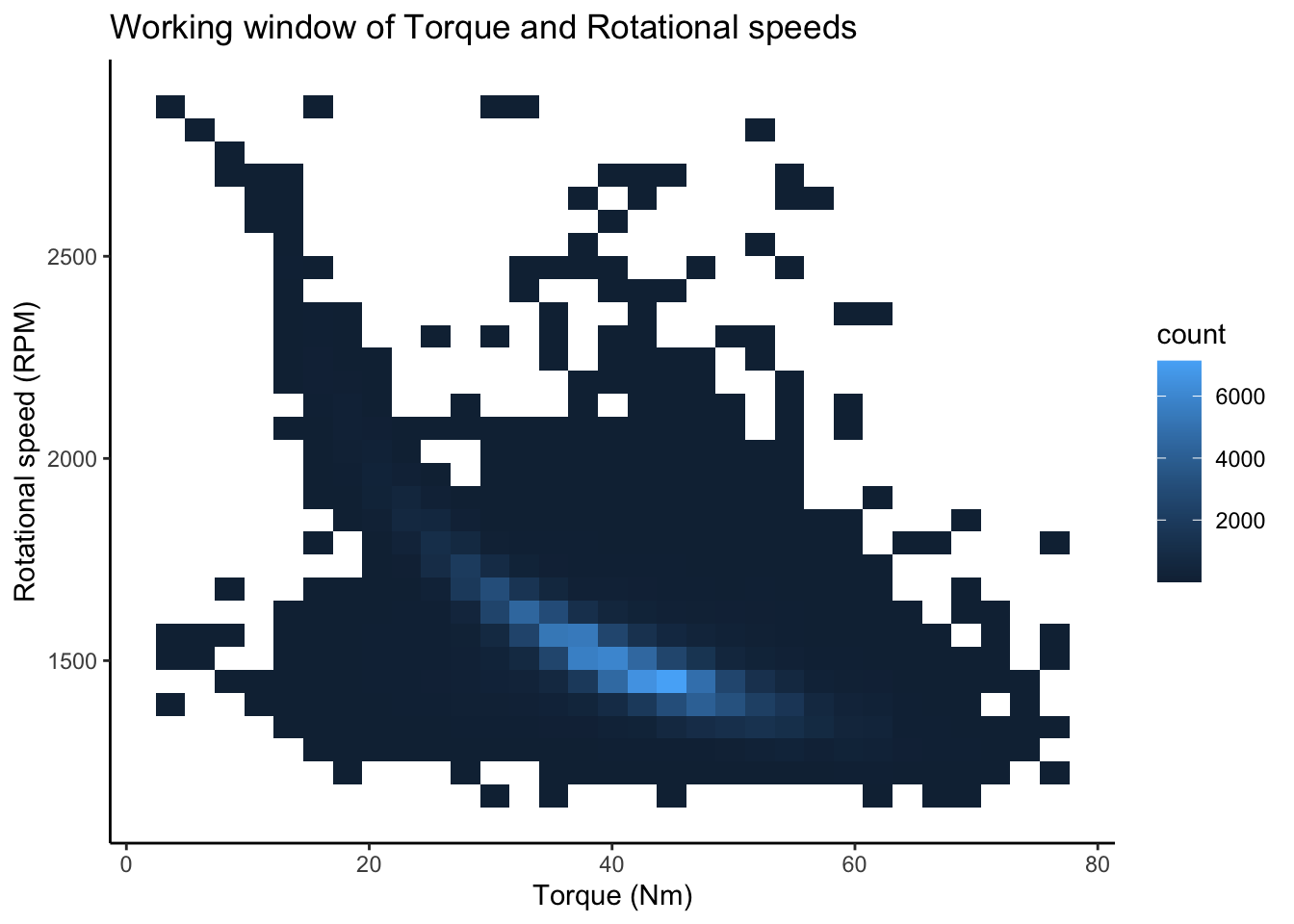
Based on the plot in figure Figure 6, we can observe
⚠️The ideal working window for torque lies between 25 Nm - 50 Nm while that for the rotational speed lies between 1250-2000 RPM . ⚠️ .
Let us now try to study how do the values for tool rotation speeds and torque vary based on power failure (PWF) faceted for each machine type.
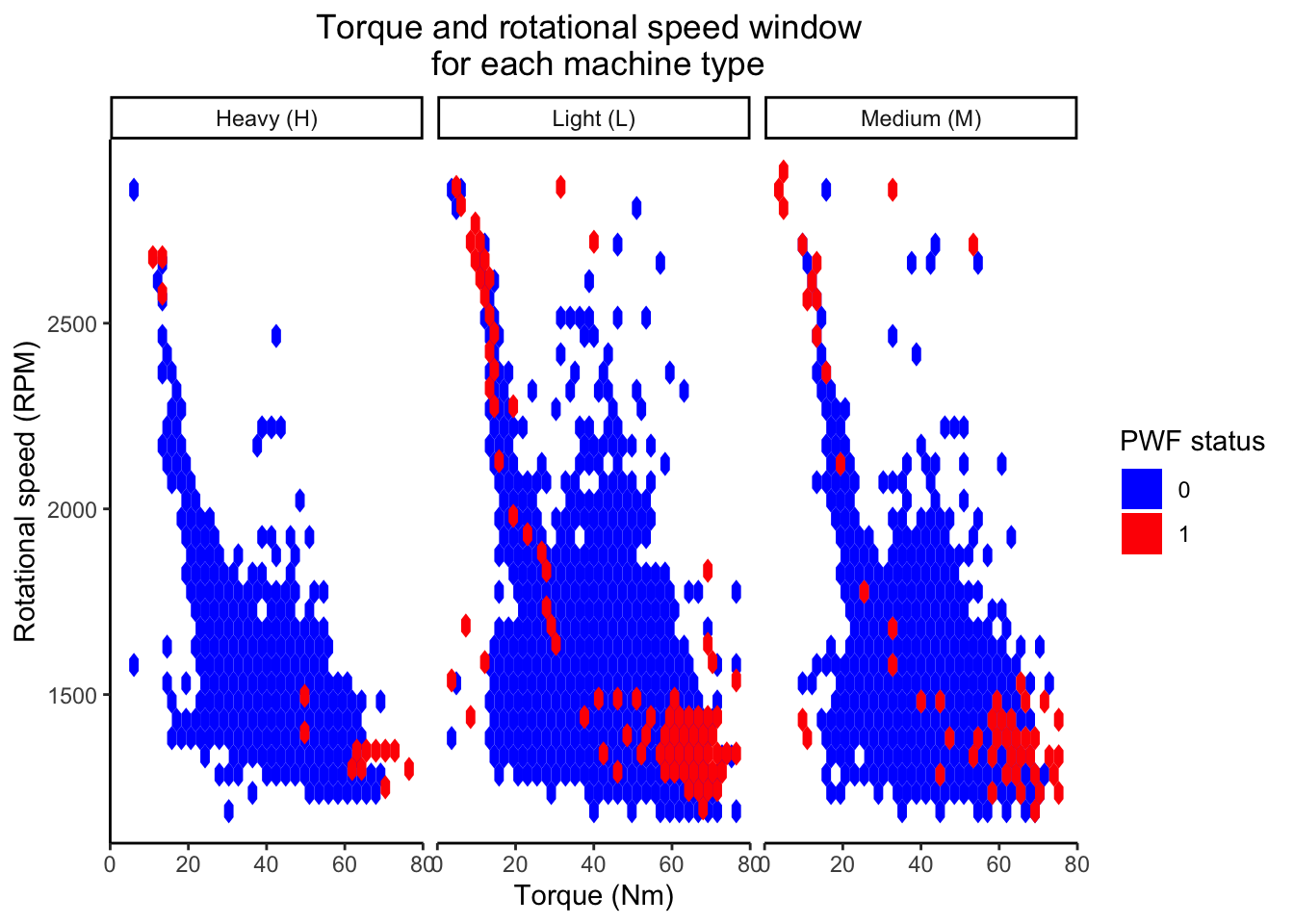
Based on the analysis of figure Figure 7 we can conclude that
❌ Power failures (PWF) are observed to majorly occur outside the ideal working window. These failures are majorly concentrated in either the regions of high torque and low rotational speeds or low torque and high rotational speeds. The observation holds consistent for all three machine types ❌ .
4.4 Power consumption
Based on the analysis in section Section 4.3, let us study how does the power consumption differ for machines which have undergone power failure (PWF).
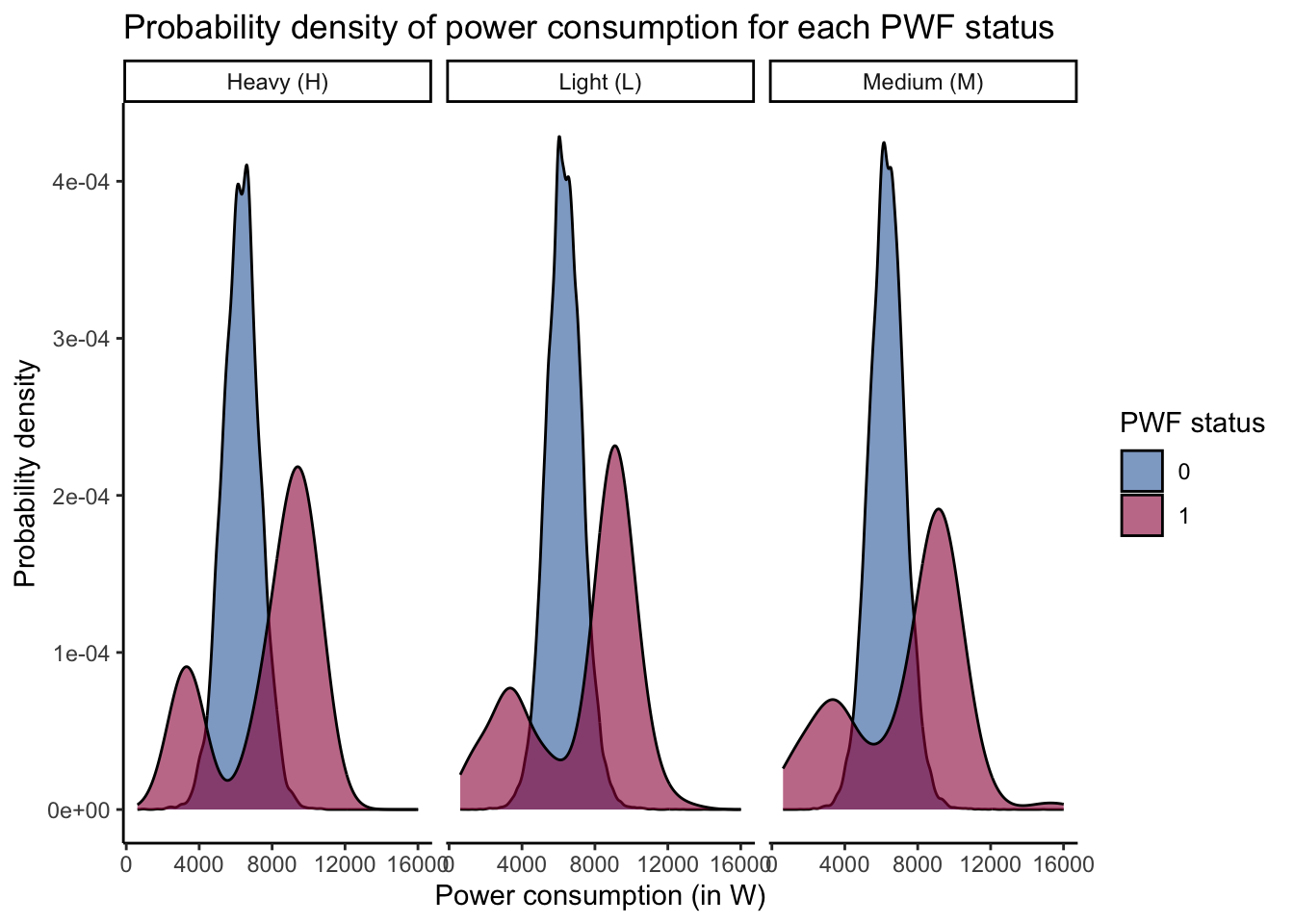
Figure Figure 8 illustrates the density distribution of power consumption for each power failure (PWF) status and faceted for each of the machine types. We can observe that:
⚡️the density plot for machines which have undergone power failure is bimodal in nature while the plot is unimodal for machines which did not undergo power failure. Based on the density plot, we can observe that the ideal working window for power consumption should be between 4000-10000 W. Machines reporting power consumption below or above this band are observed to be prone to undergo power failure.⚡️
4.5 Toolwear
The toolwear can play a critical role in terms of overstrain failure (OSF) as it can lead to excess loads on various parts of the machine equipment. Hence, it is pertinent to study the importance of toolwear through visualisations.
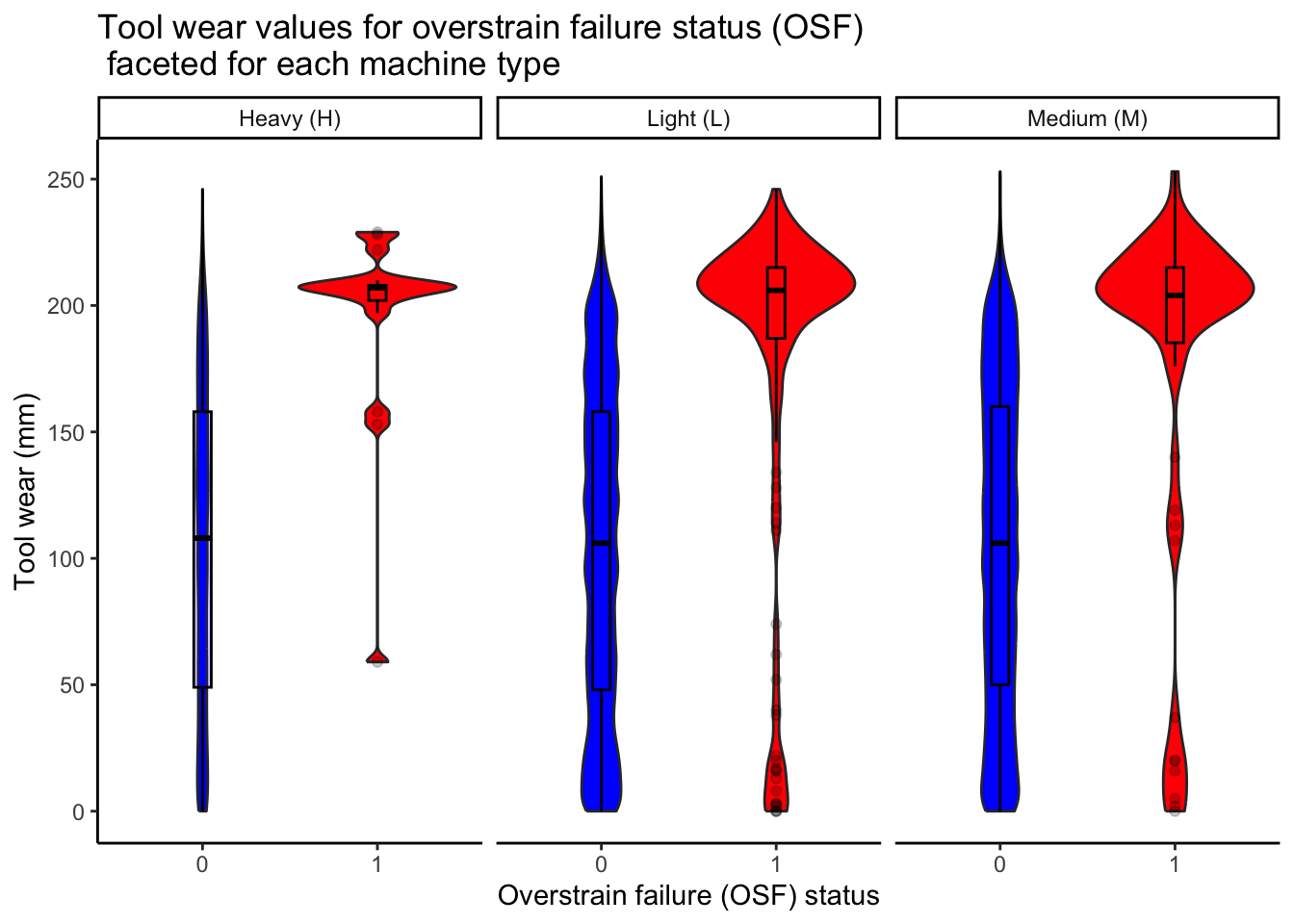
After analysing figure Figure 9, we observe that
🔩 Overstrain failures as a result of tool wear occurs majorly for tool wear values of 200 mm or above . While there are some overstrain failures at low toolwear values, however, OSF is majorly a result of higher toolwear as can be observed through the violin plots. This observation is fairly consistent for each of the three machine types. 🔩.
5 Feature Engineering
We will majorly concentrate on two new features. These features have already been analysed in sections Section 4.3 and Section 4.2. These features are namely temperature difference and power consumption.
df_train <- df_train %>% mutate(temp_diff_k = process_temperature_k - air_temperature_k) %>% select(-c(process_temperature_k,air_temperature_k))
df_train <- df_train %>% mutate(power_w = torque_nm * 2* pi * rotational_speed_rpm/60) %>% select(-c(torque_nm,rotational_speed_rpm))In the next step, we will encode the character variable for machine type into machine readable format by one hot encoding the variable as shown below.
df_train$type <- factor(df_train$type)
dt_train <- data.table(df_train)
dt_train <- one_hot(dt_train,cols = as.factor("type"))
df_train <- as.data.frame(dt_train)6 Correlation plot
After analysing the various variables and performing feature engineering, let us create a correlation plot.
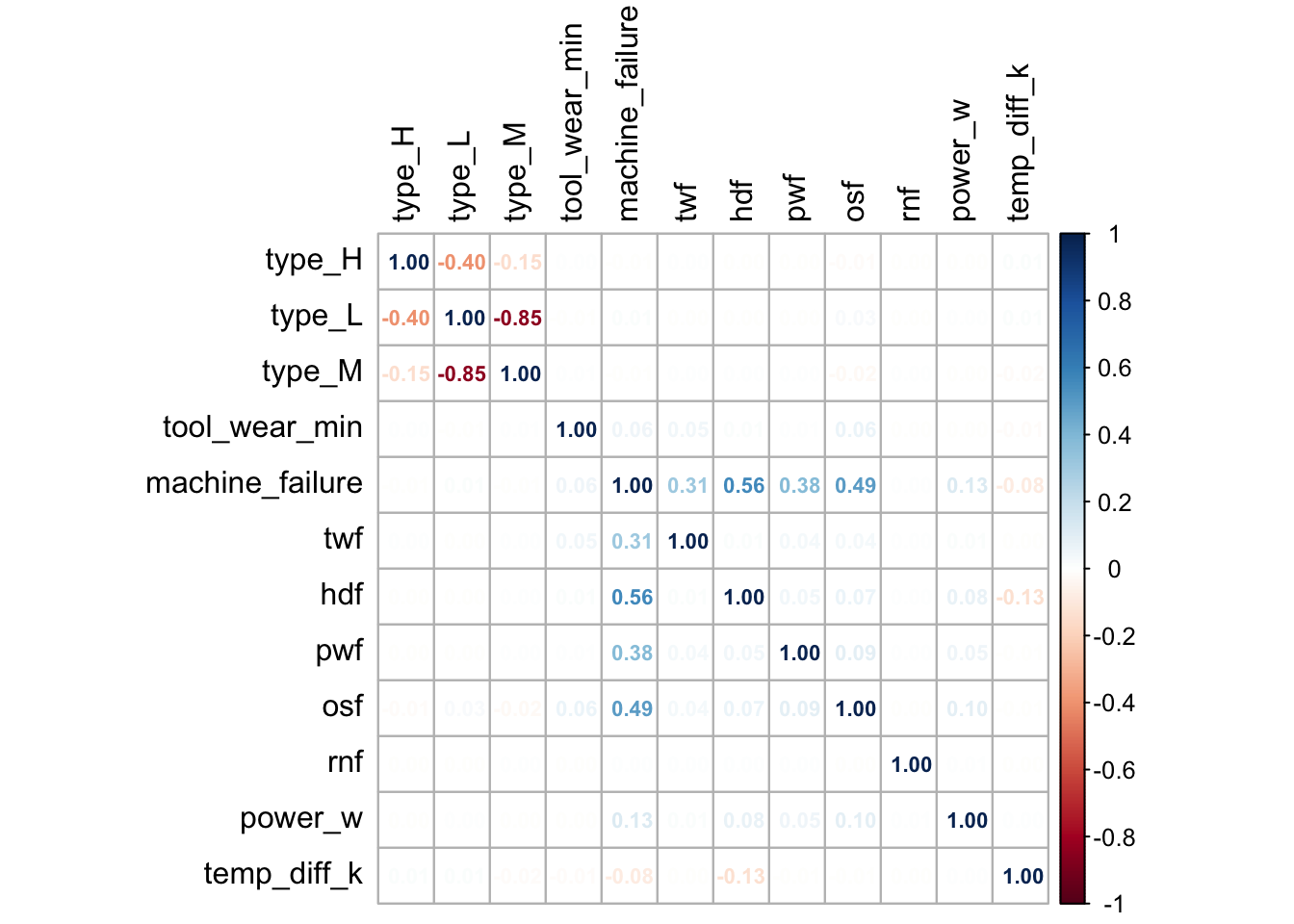
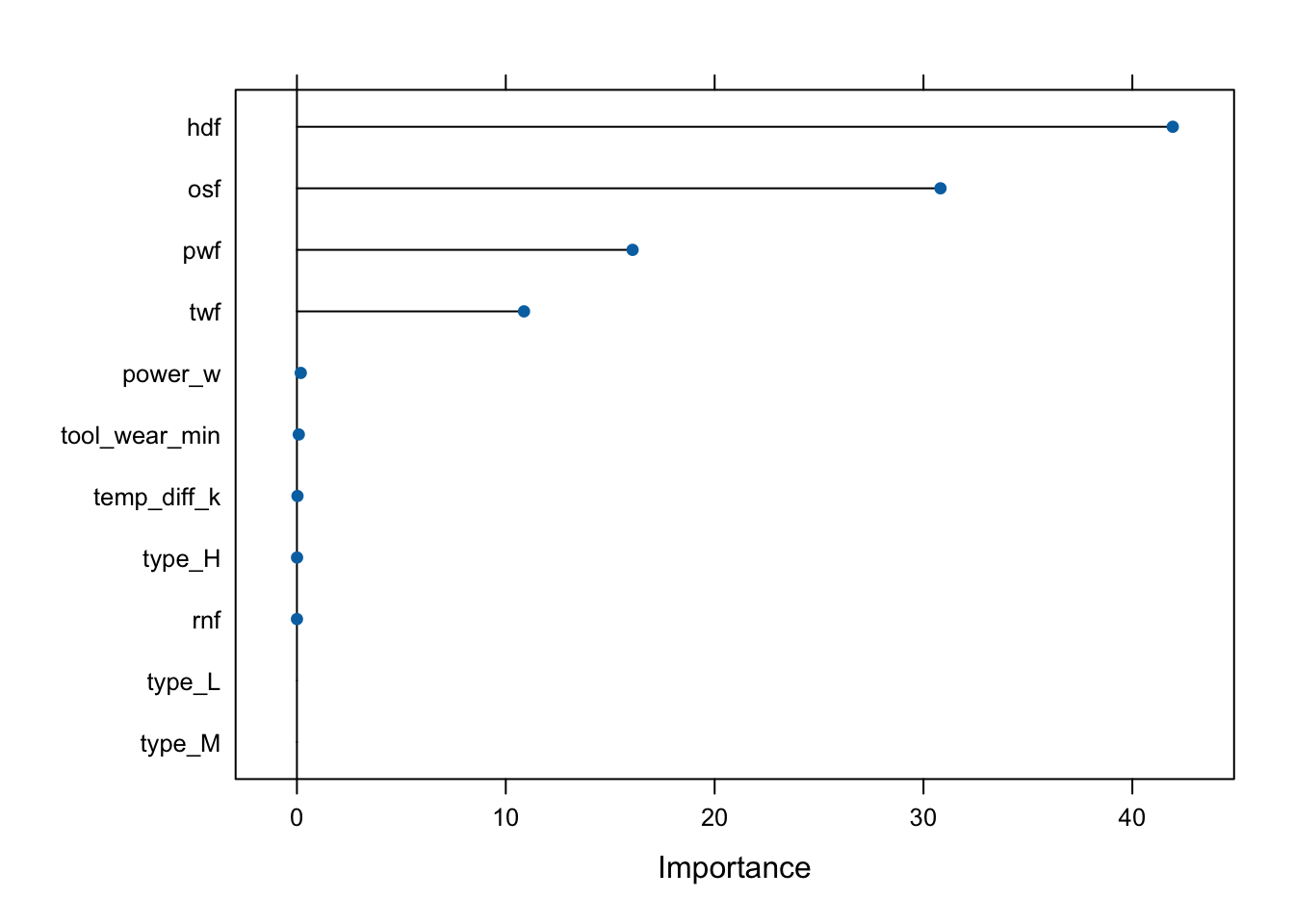
💡 Based on the above correlation plot, we can observe that machine failure has high correlation with TWF,PSF,HDF,OSF and RNF . This indicates that a failure for any of these individual variables could lead to machine failure 💡.
7 Classification model
In order to create a classification, we must first segregate the dataset into train and test datasets.
set.seed(101)
sample=sample.split(df_train$machine_failure,SplitRatio=0.7)
train=subset(df_train,sample==T)
test=subset(df_train,sample==F)After creating the required train and test dataframes, we now train the dataset by applying various classification algorithms. These have been delineated in the following sections.
7.1 Logistic Regression
model_logit <- glm(machine_failure~.,family=binomial(link='logit'),data=train)
pR2(model_logit)fitting null model for pseudo-r2 llh llhNull G2 McFadden r2ML
-2224.7236061 -7735.2112184 11020.9752246 0.7123901 0.1089918
r2CU
0.7287878 💡 Upon studying the McFadden \(R^2\) value, we observe that the model accuracy was approximately 71.2% 💡.
Let us now observe how well we can predict on the test dataset based on the logistic regression model.
[1] "Accuracy of logistic regression: 0.996090695856138"As we can observe, the logistic regression model was able to accurately predict 97.2% of the machine failures.
Let us further study the performance of the logistic regression model through the Receiver Operating Curve (ROC) metric.
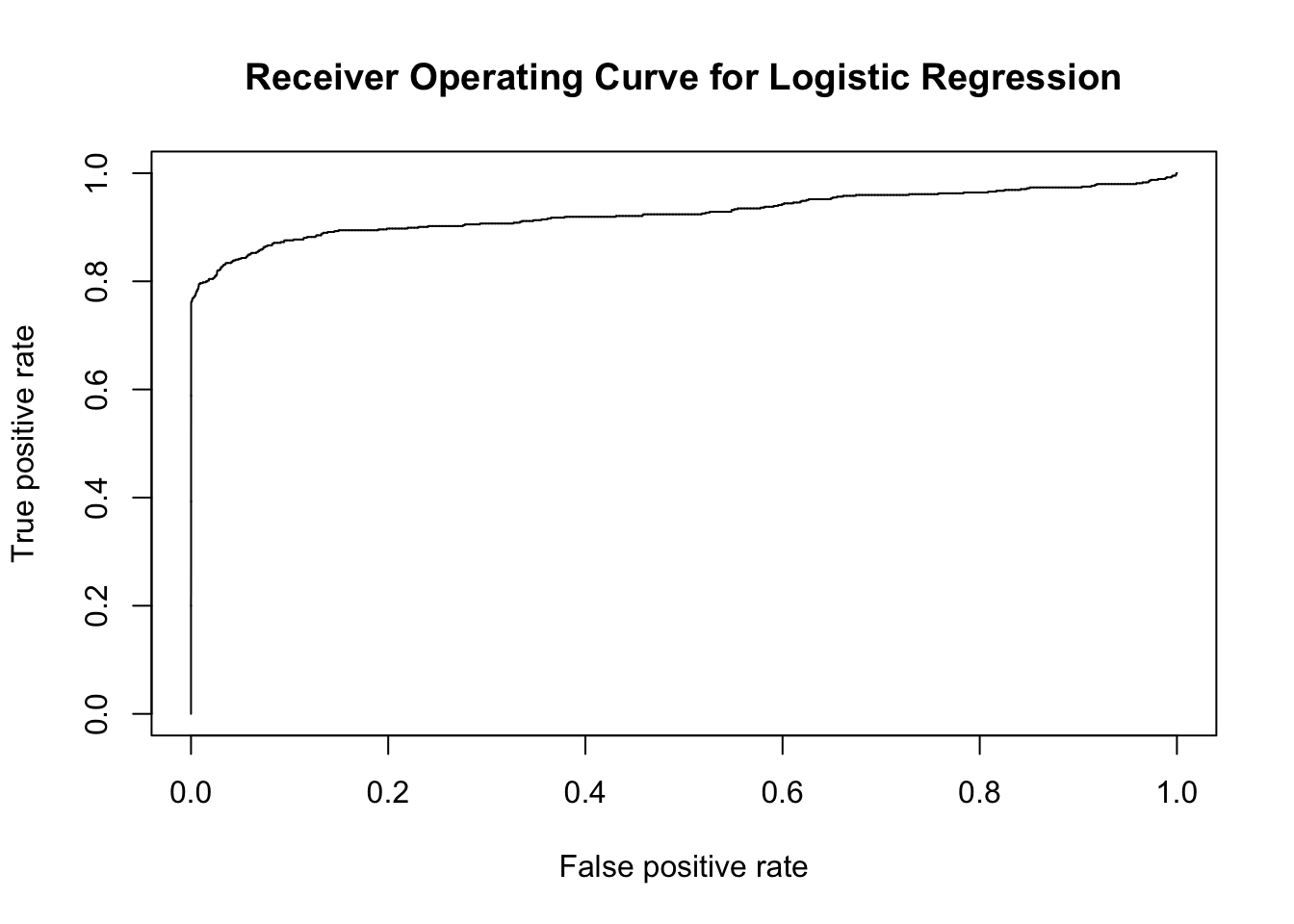
Based on the ROC as illustrated by figure Figure 11, we can observe that a large section of the upper half of the plot has been covered by the operating curve.
💡 The Area Under Curve (AUC) score of 0.9261326 suggests that the model was able to predict the machine failures fairly well. 💡
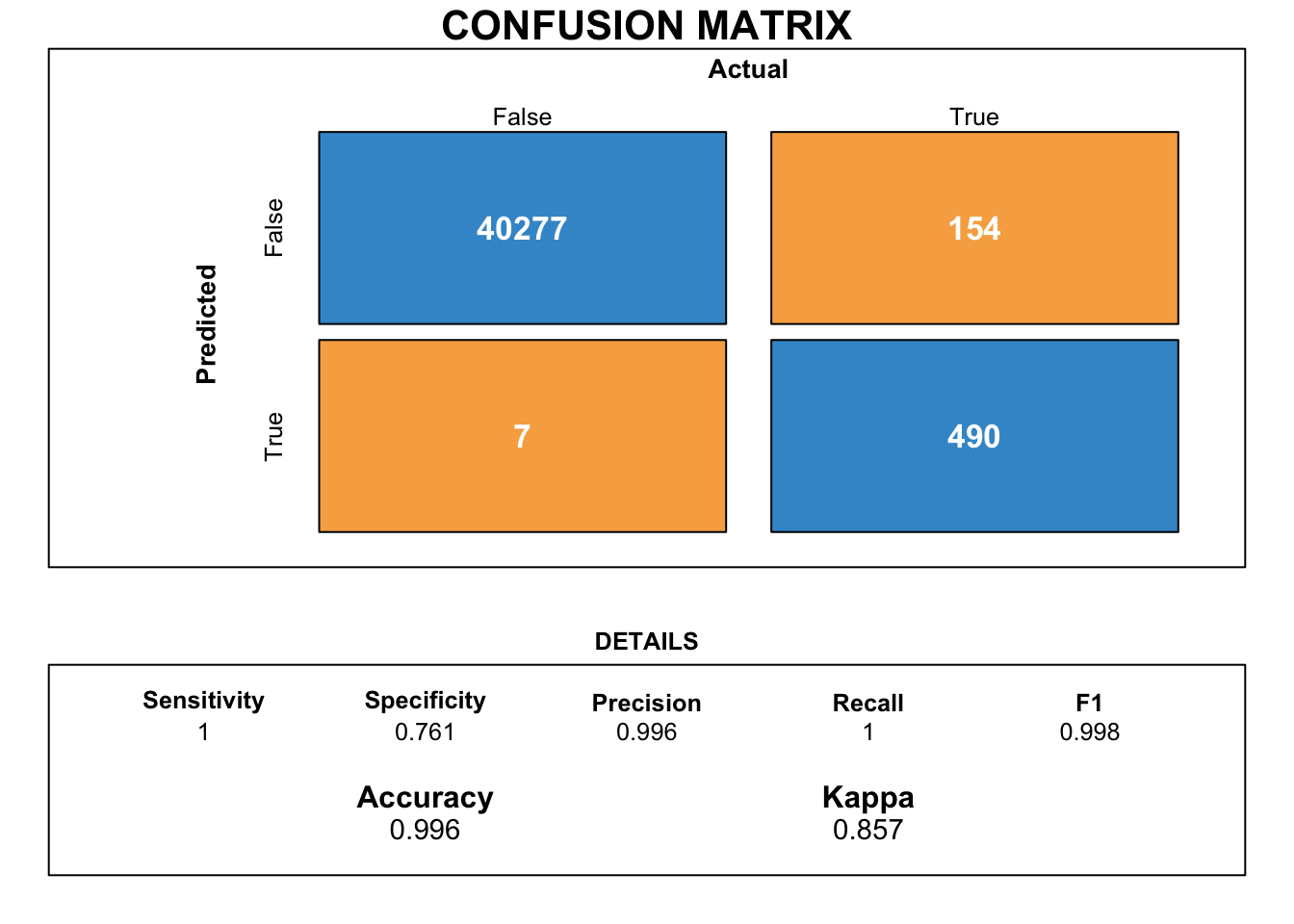
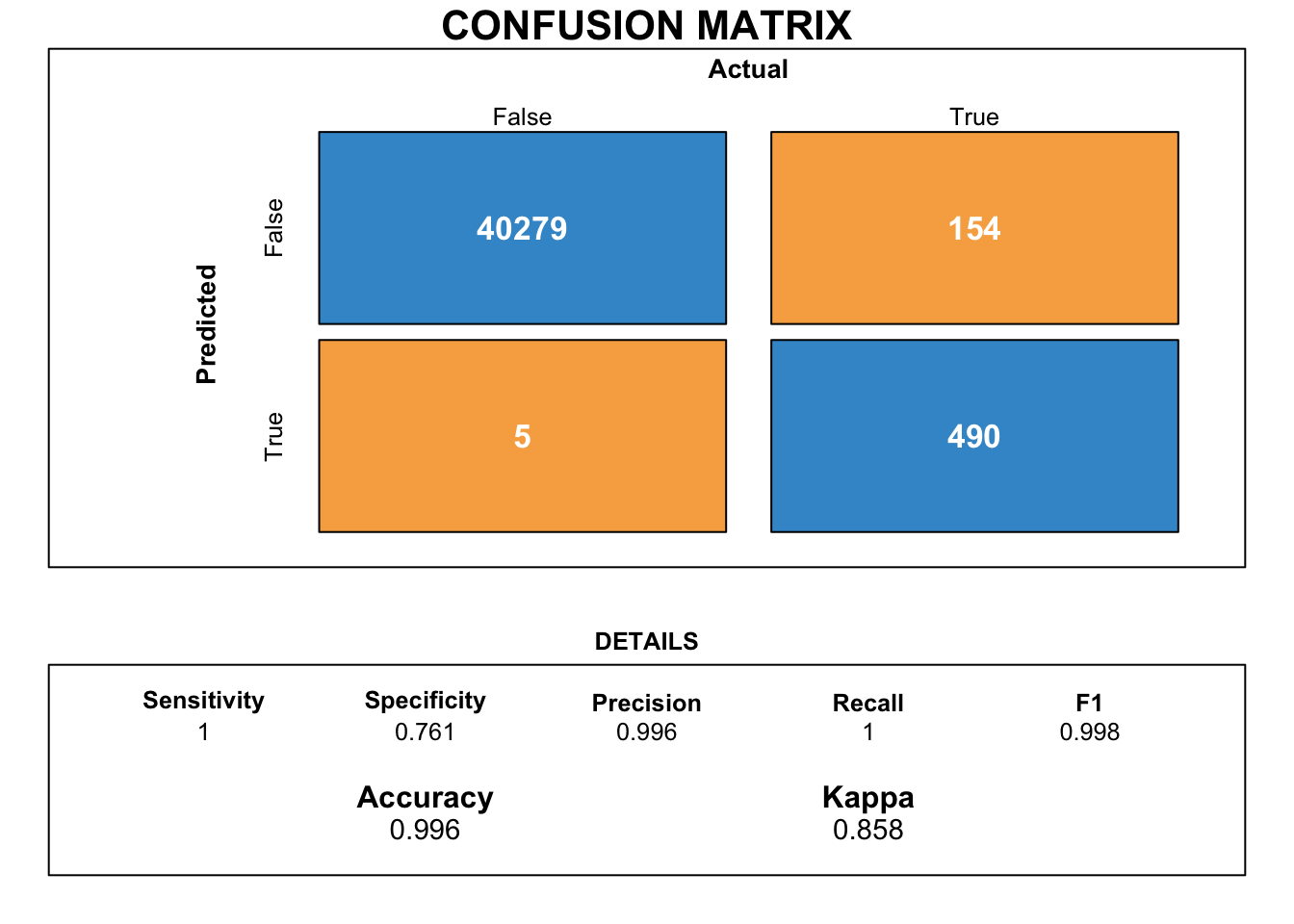
Next, we try to obtain a more intuitive performance metric of the model by creating a confusion matrix.
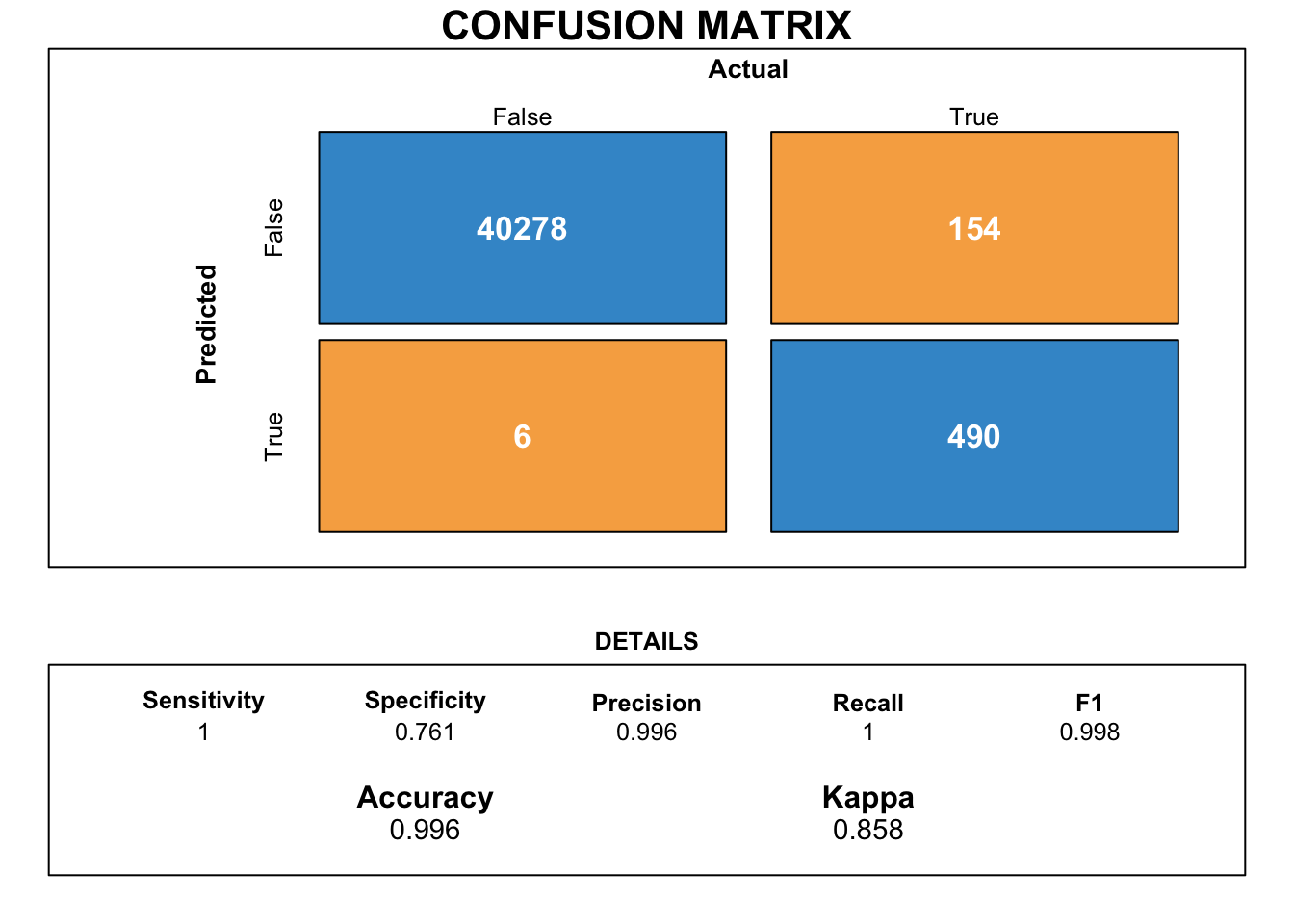
Figure Figure 12 illustrates the confusion matrix for the logistic regression model along with its various performance metrics.
7.2 Random Forest
Let us use an ensemble algorithm to classify our results. We shall utilise the Random Forest technique which utilises multiple decision trees to predict results.
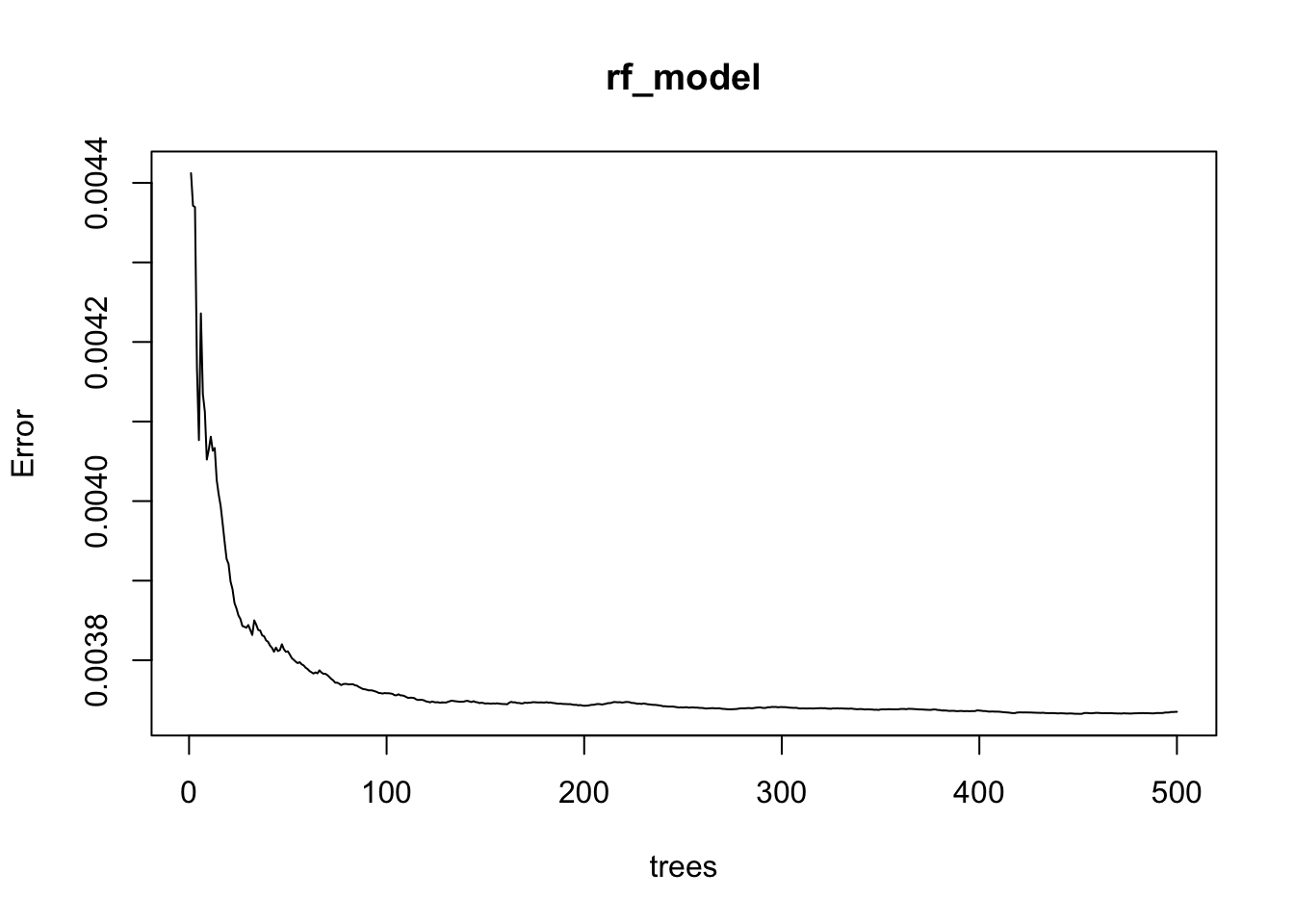
As we can observe from figure Figure 13,
💡 the error of the random forest model is observed to reduce as the number of trees cross 100 . 💡
7.3 XGboost
Let us try to use an extra gradient boosted ensemble method commonly termed as the XGboost classifier.
[1] train-logloss:0.144407
[2] train-logloss:0.059787 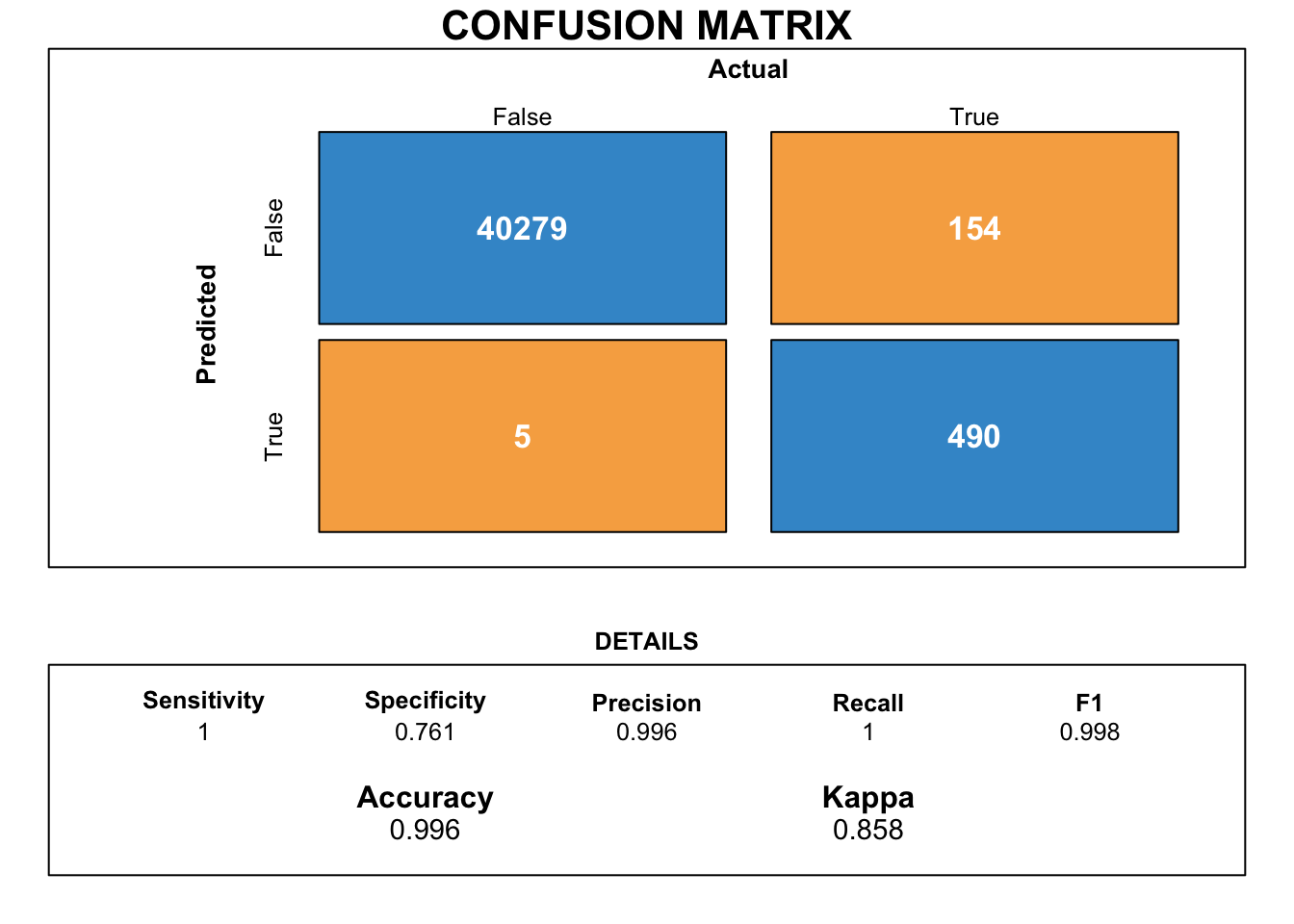
7.4 Light GBM
Let us utilise the LGBM algorithm and train it on the given dataset.
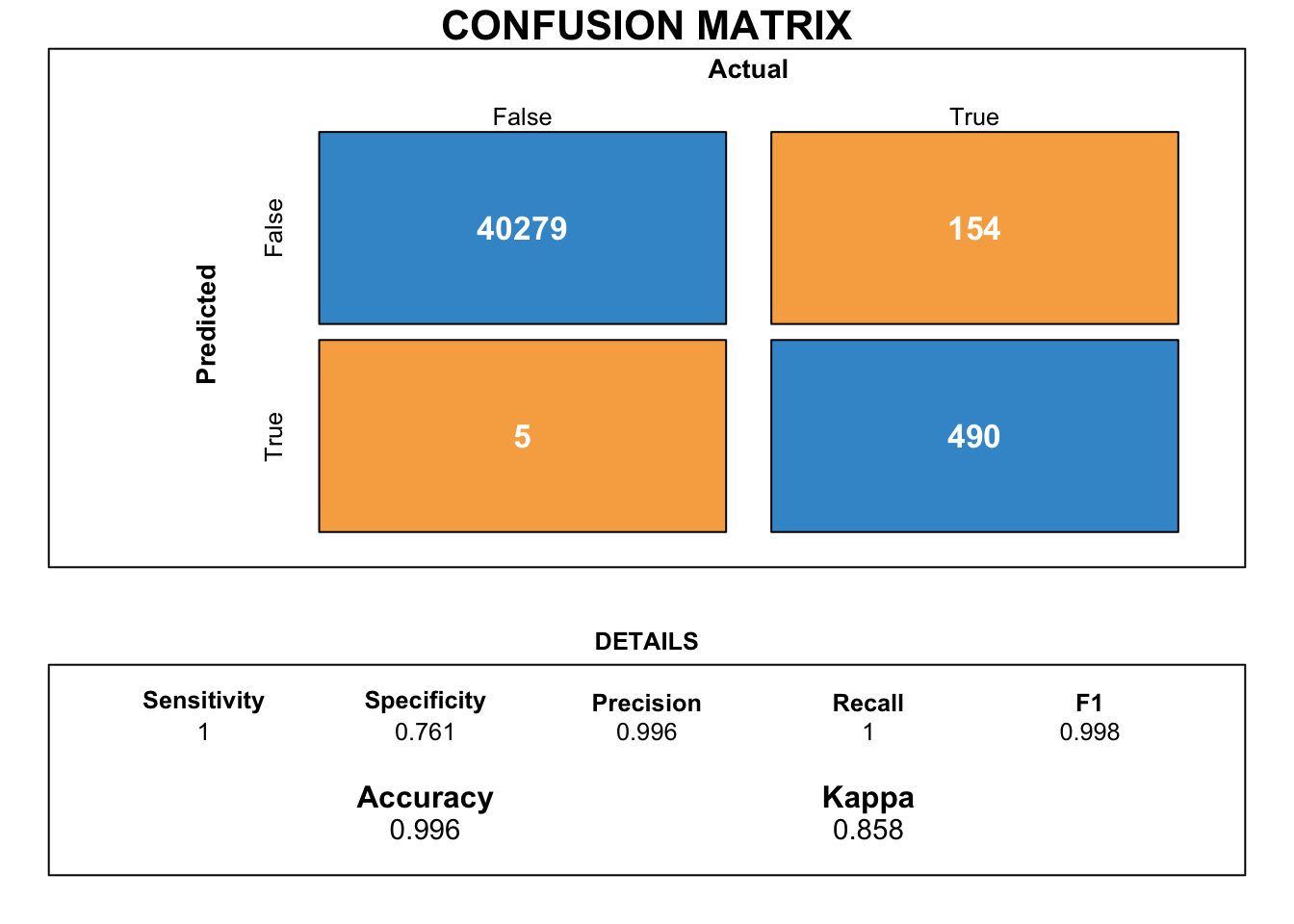
7.5 Catboost
7.6 Feature transformation and model implementation
Now that we have created all our baseline models, let us try our hand out with some feature transformation with standard scaling options.
train$tool_wear_min <- train$tool_wear_min %>% scale(center=TRUE,scale=TRUE)
train$power_w <- train$power_w %>% scale(center=TRUE,scale=TRUE)
train$temp_diff_k <- train$temp_diff_k %>% scale(center=TRUE,scale=TRUE)
test$tool_wear_min <- test$tool_wear_min %>% scale(center=TRUE,scale=TRUE)
test$power_w <- test$power_w %>% scale(center=TRUE,scale=TRUE)
test$temp_diff_k <- test$temp_diff_k %>% scale(center=TRUE,scale=TRUE)
cols <- c("twf","hdf","pwf","osf","rnf")
train %<>%
mutate_each_(funs(factor(.)),cols) #Converting to factors
test %<>%
mutate_each_(funs(factor(.)),cols)
df_test %<>%
mutate_each_(funs(factor(.)),cols)Now that we have standardised all the continuous numeric variables, let us attempt to train the model once again on the scaled dataset.
model_logit <- glm(machine_failure~.,family=binomial(link='logit'),data=train)
pR2(model_logit)fitting null model for pseudo-r2 llh llhNull G2 McFadden r2ML
-2224.7236061 -7735.2112184 11020.9752246 0.7123901 0.1089918
r2CU
0.7287878 [1] "Accuracy of logistic regression: 0.996090695856138"